Game Development
I’ve been wanting to create a very specific kind of game for a few years now. Game Development was one of the reasons why I initially became interested in software development, but I quickly lost interest in it relative to other areas that piqued my interests. Still, I was always interested in Game Development, particularly with how it seemed to me like a tour de force in software development, requiring expertise in a variety of areas in order to produce a working game.
Over the years I’ve tried to learn about various different areas of software development, as orthogonal as possible, to gain as much perspective and become more well rounded. These new things I’ve learned have provided me with insight and a “bigger picture” with regards to game development, to the point where I feel more strongly than before that I should at least attempt to create the game I’ve had in mind. For preparation, last year I read a book on 3D Math that solely concerned itself with the math, and one on Direct3D 11.
Architecture
New Approach
I’m taking a step back from the overly general architecture discussed in the following sections, consisting of “components everywhere” and a very loose, omnipresent event system that sacrificed the type system. I originally chose to create my engine from scratch because I wanted to use this as a learning experience, but also to have absolute control over what I want to create. However, I’m well aware of the countless games that roll their own engine only to still be working on the engine for years with no game to show for it. I don’t want that to happen here.
My opinion is that this tends to happen because people want to make their engine be everything: fully cross-platform and fully general so that it can scale from a mobile F2P game to a next-gen racing game and further still to an FPS. I’m reminded of the days of the Quake 3 engine, which—despite my limited experience with it—didn’t seem to strive to be everything for everyone, and yet many people adapted it to accommodate all manner of different game types.
There is clearly a balance between creating a game and creating a general engine. The end goal is the game, but it’s not necessary to completely sacrifice good software architecture practices, specifically those associated with game engine design (e.g. components, event systems, etc.).
The approach I’m going to try now is to focus on creating a game, leaning towards a game-specific engine, while being sensitive to potential refactorings. These potential refactorings will be a lot clearer to me than to write them from the beginning, since I will have a concrete example of exactly where and why they might be useful.
Anyone who has ever tried to learn anything about game engine design is familiar with the ever-present author disclaimer that goes something like “keep in mind this works in our particular engine, but circumstances in your engine may differ.” Being new to game engine design, the task of designing a well architected, flexible engine from the start seems too open-ended. That’s why I’m taking this approach, in order to help guide the process.
Components
Every Actor has a collection of Component objects which compose to define the whole of a particular Actor, including its attributes and behavior. Some Components are tied to a specific Engine subsystem, such as RenderableComponent. All these do is notify the particular subsystem of their existence so that they can be used. For example, the Renderer subsystem would receive the event from a MeshComponent and so would update its list of meshes to render on the next frame.
Events
The Engine has Components/Susbystems such as Renderer, Game, Audio, etc. Game has collection of Actors, and Actors have collection of Components. This hierarchy forms a chain of responsibility up to the Engine.
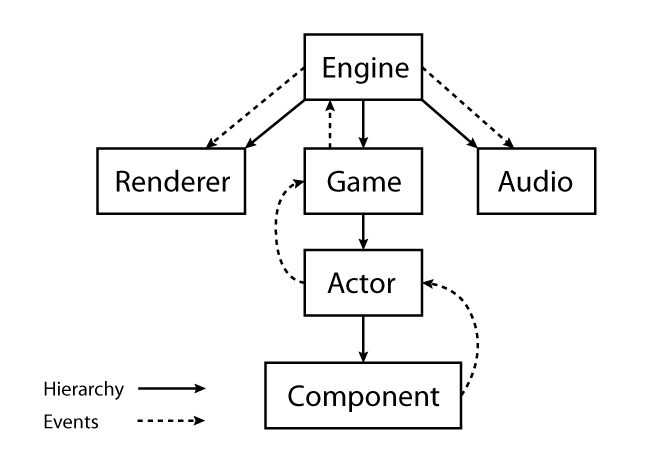
The chain of responsibility forms an event-handler hierarchy. Each Event is derived from a base event that has scope and subject properties.
The scope consists of the system the event is meant for. For example, a Component event would be Component, whereas an event meant for the renderer would be Renderer. This allows fast forwarding of events through the chain of responsibility.
The subject itself is the event’s identifier, for example, “player died.” A particular derived Event would have appropriate data for this event which might be necessary for its handling.
To forgo Run-Time Type Information (RTTI) and its associated performance cost, some sort of lookup table is used to determine the type of message to then static_cast it to the appropriate event, in order to allow simply having an OnEvent-type function with a base Event parameter.
For example (tentative), when a MeshComponent is added to an Actor, it’ll want to register itself with the Renderer by sending a MeshAdded event which contains a shared_ptr to the MeshComponent. The MeshAdded event might look something like this:
class MeshAdded : public RendererEvent {
public:
MeshAdded(std::shared_ptr<MeshComponent> mesh) :
subject_(RendererEvent::Subject::MeshAdded),
mesh_(mesh) {}
std::shared_ptr<MeshComponent> mesh() const;
private:
std::shared_ptr<MeshComponent> mesh_;
};
When a MeshComponent is added to an Actor, it sends this MeshAdded event to the Actor because it is the nearest possible handler in the chain of responsibility. The Actor recognizes that it is out of its scope, so it passes it up the chain of responsibility to the Game, which does the same. When the event reaches the Engine, it forwards the event to the Renderer component which finally handles it appropriately. The Renderer handles it by adding the mesh to its list of meshes to be rendered on the next frame. When the MeshComponent is removed from the Actor, it sends an event so that the mesh is removed from the list.
The per-event scope allows the chain of responsibility to fast-forward events which are out of the current handler system’s scope. For example, in the example above, as soon as the Actor and Game systems noticed the event of scope Renderer, it didn’t bother to see if any of its registered handlers could handle the event and instead forwarded it up the chain as soon as possible.
Similarly, it could be beneficial for each system to allow components to register interest in events. With such a system, if there are 100 Actors but only 2 of them are interested in a particular event, only those 2 interested Actors would be sent the event instead sending the event to all 100 Actors to determine which are capable of handling it. This can be accomplished by a map from event subject to a list of interested handlers:
std::unordered_map<GameEvent::Subject,
std::vector<std::shared_ptr<Actor>>> handlers_;
handlers[GameEvent::Subject::PlayerDied].push_back(someActor);
The event loop for Game can then look something like this:
void OnEvent(const Event &event) {
if (event.scope() != Event::Scope::Game) {
this->parent_->OnEvent(event);
return;
}
for (auto &handler : handlers[event.subject()])
handler.OnEvent(event);
}
Input
Have an Input subsystem. In the SDL event loop, feed key events to the Input subsystem. The Game can be a mediator. The InputComponents register interest in Game actions such as Jump. The Game contains a map of the key bindings mapping action-to-key, as well as a map of action-to-components. If an action has even one registered InputComponent, then the Game registers an interest in the key for that action with the Input subsystem. When the Input subsystem detects that this key is pressed, for example, it notifies the Game of this, which translates it into a Game action and forwards it to every registered InputComponent.
- robust input handling
- input in component-based systems
- input in component-based system #2
- input in large games
Optimizations
Object state caching entails an object keeping a “double buffer” of its state: one for the previously calculated state, and another for the to-be calculated state. This helps, but doesn’t completely solve, the problem of one-frame-off lag. It also allows for easy interpolation between two states for easy feeding into an interpolating render function. This only guarantees that the previous frame’s state is fully consistent, but not the current state.
- quaternion rotation without euler angles
- renderable components
- physics and renderable components
- order draw calls
- materials in a component system
- Evolve your hierarchy
- Custom 2D Physics engine core
- Component based games in practice
- Component based object traversal
- Should an object in a 2D game render itself?
- Should actors in a game be responsible for drawing themselves?
- Tactics for moving the render logic out of the GameObject class
- Separation of game and rendering logic
- Scene graphs and spatial partitioning structures: What do you really need?
Build System
The best build system for a game in my opinion is CMake, which can generate build files on various platforms. Perhaps the only thing that bothered me about developing on Windows was the fact that all settings were mainly configured through a GUI, hidden in various sections and so on. This felt very haphazard to me, mainly difficult to grok which settings were manually specified.
With CMake, I can define all of the settings I want in a CMake file and have a neat Visual Studio project be generated from it. Likewise on POSIX systems, Makefiles are automatically created.
Game Loop
The game loop isn’t as cut and dry as I used to think. There are a variety of considerations:
- Game Loop
- Fix your timestep
- deWitter’s game loop
- Fixed time step vs variable time step
- Casey and the clearly deterministic contraptions
Rendering
One of the major questions in engine architecture is the decoupling of rendering from actors. It seemed to me that having the actors draw themselves contradicted very fundamental software development principles, such as single responsibility and separation of concerns.
The main idea behind the solution to this problem, that I have read about, is to define a separate renderer class. This is the class that will concern itself with rendering things.
There is a common data structure called a scene graph that is a hierarchical representation of coordinate space relationships, specifically for the purpose of facilitating transformations on groups of related objects. For example, a player mesh that holds a weapon mesh in its hands would be represented in the scene graph as a player node with a weapon child node. If the player node is translated or rotated, the transformation will carry through to the weapon node.
Aside from this scene graph representation, there would also be another data structure for the purposes of space partitioning, to facilitate visibility testing, such as Binary Space Partitions or Octrees.
If using an octree, keep some threshold number of meshes per node to avoid excessive partitioning. Similarly, if a mesh fits in multiple partitions then it should appear in each of them. When objects move, the list of meshes in each partition should be modified to represent this change. Too many or too few meshes in a partition might require partitioning or merging, respectively.
The rendering phase can then be divided into visibility determination and actual rendering. The octree is traversed to collect visible objects. These objects are added to specific buckets pertaining to their shader type, and during rendering these buckets are rendered sequentially to avoid unnecessary/duplicate state changes.
The engine I’m creating so far consists of actors that are component-based. I feel that perhaps it would be possible to define a mesh component, for example, that contains relevant information. The actors can use the visitor pattern so that, on traversal of the scene graph, the renderer calls the actor’s render method which fetches any renderable components and delegates the rendering back to the renderer. TODO: Is that a good idea? What would constitute a “renderable” component? Enforcing this in static code would seemingly do away with the benefits of run-time composition?
Major Notation
I learned linear algebra and related 3D math using math and Direct3D texts which both used left-handed coordinate systems and row-major notation. Transitioning to the right-handed system of OpenGL, I was aware of some of the differences, such as reversing the order of matrix concatenations, but I was a bit uncertain about everything entailed in usng the different system. I found a pretty good article on the topic. What follows are my notes from reading that article.
Handedness
The handedness of a system has an effect on the directions of the positive $z$-axis, positive rotation, and the cross-product. These can easily be determined by using the right-hand rule or left-hand rule. It’s important to realize that this has nothing to do with row or column-major notation.
Representation
Row-major notation means that when indexing or denoting a matrix’ size, the row is written first, and vice versa with column-major notation. Given a row-major matrix $R$, the column-major matrix $C$ is derived by deriving the transpose $R^{T}$:
Storage
When it comes to matrix storage in memory, the key is that they are both stored the same way. A row-major matrix is stored in contiguous memory one row at a time, whereas a column-major matrix is stored one column at a time. The implication is that a stored row-major matrix can be passed to an API that expects column-major matrices without needing to transpose the matrix first.
Multiplication
When multiplying vectors with matrices, row-major notation requires pre-multiplication; the vector must appear to the left of the matrix. Column-major notation requires post-multiplication. This has the effect that the row-major, pre-multiplication transformation:
Must be expressed as follows in column-major notation:
However, row-major and column-major matrices are already transposes of each other, and as a result they are stored the same way in memory. This means that no actual transposing has to take place!
Voxel Engine
I’d like to have voxel-based terrain (no, it’s not a minecraft clone) so it’s important to keep in mind that there are a variety of efficiency questions involved in creating a robust engine for this kind of world.
Chunks
The most common optimization is to treat the world as a composition of chunks, each chunk being a composition of WxHxD voxels, Minecraft uses a logical chunk size of 16x16x256 and graphics chunk size of 16x16x16. Chunks have a variety of purposes. One of them is that they do away with having to instantiate a multitude of individual voxel objects. Instead, chunks are in charge of keeping the information of the blocks that constitute it.
A chunk may be represented by a volumetric grid such as a 3D array, optimized into a flat slab of memory indexed with the formula:
The problem with this is that a lot of space is wasted for empty cells. A 16x16x16 chunk size where every cell conveys its information within one byte of data yields 4096 bytes, or 4 kilobytes. If every single cell in the chunk is empty except for one, then 4095 bytes are being wasted. That’s 99.9% of the space allocated for the chunk.
One solution to this is to use something similar to a sparse matrix. Specifically, the chunk can be represented by a hash table keyed by tuples corresponding to the coordinates within the chunk. This way all cells are implicitly empty cells unless present in the hash table. During the mesh construction phase, the hash table can be iterated for every non-empty cell. Similarly, the hash table can provide amortized constant access to specific cells in the chunk.
Another common solution to this is to use Run-Length Encoding compression on the volumetric grid. However, this probably doesn’t have the same near-constant access benefit as hash tables.
Overdraw
One problem with voxel terrain is that it easily allows for overdraw, where non-visible geometry is passed to the GPU for rendering. Non-visible geometry in this case refers to the traditional cases of geometry being outside of the view frustum and geometry occluded by other geometry.
In voxel engines, however, the second case—occluded geometry—can also be very important with regards to inter-chunk, non-visible faces. That is, given a 2x2x2 chunk, there is no need to render the faces that intersect the chunk, i.e. the inner faces. The natural solution to this is to cull the interior faces by querying the neighbors during chunk geometry generation.
A further optimization is back-face culling. This can be done on the GPU based on the ordering of the vertices, but it can also be done on the CPU thereby avoiding the unnecessary transfer of the data. A way to accomplish this is to have separate vertex buffers for the different sides of the chunk. Then, depending on the position of the camera, only sending those buffers that are visible.
Another optimization yet is a higher-level one that would occur before most other ones is known as frustum culling: disregarding geometry that isn’t within the camera’s view frustum. This would be performed at chunk-level granularity. An octree can be used to quickly determine chunks that are visible by the camera.
- OpenGL Volume Rendering: very nice modern C++11
- GLBlox: from the above. nice modern C++11
- Something other than Vertex Welding with Texture Atlas?
- Voxel Face Crawling (Mesh simplification, possibly using greedy)
- An Analysis of Minecraft-like Engines
- Meshing in a Minecraft Game
- Ambient Occlusion for Minecraft-like worlds
- Texture atlases, wrapping and mip mapping
- Sea of Memes
- Polygon Triangulation
- Simple, Fast Polygon Reduction Algorithm
- Smooth Voxel Terrain
- Polygonising a Scalar field
- Triangulation
- Minecraft from a Developer’s Perspective
- In what kind of variable type is the player position stored on a MMORPG such as WoW?
- Dungeon Seige Publications
- For voxel rendering, what is more efficient: pre-made VBO or a geometry shader?
- Computing normals in fragment shaders
- PolyVox
- Terasology, Source
- From Voxels to Polygons
- Voxel Relaxation
Terrain Generation
Infinite worlds have eventual limits mainly due to round-off errors with floating point numbers. Minecraft tries to mitigate this by using local coordinates:
Many of these problems can be solved by changing the math into a local model centered around the player so the numbers all have vaguely the same magnitude. For rendering, Minecraft already uses local coordinates within the block and offset the block position relative to the player to give the impression of the player moving. This is mostly due to OpenGL using 32 bit floats for positions, but also because the rounding errors are extremely visible when displayed on a screen.
Notch on Terrain Generation
Terrain generation is usually accomplished with noise:
- Terasology Terrain Generation
- Simplex Noise
- Perlin Noise: See section on wood textures
- Perlin Noise 2
- Terrain Generation: Hills
- Terrain Generation: 3D Perlin Noise
- Endless Chunks
- Handling chunk edges
- Tileable Perlin Noise
- Forum Post
- Scale GLM Perlin Noise
- Procedural Color Palette Generation
- Perlin Noise Implementation
- More Procedural Voxel World Generation
- Revisiting the block worlds stuff
- More on Minecraft-type world gen
SDL
On Windows, the Visual Studio builds are built using a different run-time library and necessitates building manually with the /MD or /MDd linker options for Debug and Release respectively to avoid annoying warnings.
The SDL_SetWindowFullscreen function takes two parameters as is shown in the wiki page:
SDL_WINDOW_FULLSCREEN: simply sets the window, with the same display mode (res & rr), to be full screenSDL_WINDOW_FULLSCREEN_DESKTOP: takes the desktop’s display mode and fullscreens; very fast alt-tabbing since it doesn’t require video mode change?
It seems that, to set a specific display mode, it should first be found by enumerating the display modes with SDL_GetNumDisplayModes, a specific one retrieved with SDL_GetDisplayMode, then set with SDL_SetWindowDisplayMode, followed by a call to SDL_SetWindowFullscreen with the SDL_WINDOW_FULLSCREEN option to change the video mode to fullscreen.